Building NumPy and SciPy with GotoBLAS2
NumPyとSciPyをGotoBLAS2を使ってbuildした時のメモ。ここの通りにやっても出来なかったのでいろいろ試行錯誤した残骸。環境は以下の通り。
- Linux MInt 12 32bit (Ubuntu 11.10ベース)
- Core2 Quad
- gcc-4.6
ちなみに私は共有ライブラリだけでやっていますのでstaticライブラリも欲しい人は適当に修正してください。
また、事前に/usr/local/libにLD_LIBRARY_PATHを通しておいてください。 ldconfigも適宜実行。
2012-Feb-27 修正
* NumPyのsite.cfgの表記を修正
* LAPACKのbuildを修正
2012-Mar-26
* 誤字を修正
* LAPACKのbuildを修正
GotoBLAS2
Ubuntu 11.10以降からはOpenBLASというパッケージが配布されています。それを入れるのが一番早いですが、一応ここは手でbuild!!
- SurviveGotoBLAS2をここから入手。解凍してMakefile.ruleを編集。以下をコメントイン。
* TARGET = CORE2 (TARGETの一覧は付属の01.Readme.txtにある。
* BINARY=32 (32bit)
* USE_THREAD = 1 (threadを使う)
* USE_OPENMP = 1 (OpenMPを使う)
* NUM_THREADS = 4 (最大4threadsまで)
* NO_CBLAS = 1 (CBLASは自分でbuildする)
* NO_LAPACK = 1 (LAPACKも自分でry) - $make all -j 4
- 念のために共有ライブラリを作りなおす。(ソースはstackoverflow)
$mkdir temp
$cd temp
$cp ../libgoto2.a
$ar -x libgoto2.a (staticライブラリを.oファイルにばらす)
$gfortran -shared -lpthread -lgomp -o libgoto2.so *.o (共有ライブラリを作成)
$sudo cp libgoto2.so /usr/local/lib - (重要) atlasにリネームしておく。 numpyのbuildの時に必要
$cd /usr/local/lib
$sudo ln -s libgoto2.so libatlas.so
$sudo ln -s libatlas.so libf77blas.so
$sudo ln -s libf77blas.so libptf77blas.so
CBLAS
- CBLASをNetlibから取ってきて解凍。
- cp Makefile.LINUX Makefile.in
- Makefile.inのCFLAGSとFFLAGSに”-fPIC”を足しておく
- $make all -j 4, これでlibにcblas_LINUX.aができている.
- .oファイルから共有ライブラリを作る
$ gfortran -shared src/*.o -o libcblas.so - ライブラリディレクトリにコピー&リンクの作成
$sudo cp libcblas.so /usr/local/lib
$cd /usr/local/lib
$sudo ln -s libcblas.so libptcblas.so
LAPACK
- LAPACKをNetlibから取ってきて解凍。
- $cp make.inc.example make.inc
(optional) make.incの”-O2″を”-O3″に変更。
make.incかSRC/Makefileに”-fPIC”をつけておく。
$make lapacklib -j 4 (テストは面倒なので飛ばします。ちゃんとやりたい人はallで) - 共有ライブラリを作成
$mkdir temp
$cd temp
$cp ../liblapack.a .
$ar -x liblapack.a (staticライブラリをばらす)
$gfortran -shared -o liblapack.so *.o - ライブラリディレクトリにコピー
$sudo cp liblapack.so /usr/local/lib
NumPy
- NumPyのソースを公式サイトからダウンロードして解凍
- $cp site.cfg.example site.cfg
- site.cfgを編集
[DEFAULT]
library_dirs = /usr/local/lib
include_dirs = /usr/local/include[blas_opt]
libraries = ptf77blas, ptcblas, atlas[lapack_opt]
libraries = lapack, ptf77blas, ptcblas, atlas - 設定内容の確認
$python setup.py config - numpyのbuild&install
$python setup.py
$sudo python setup.py install
buildしたnumpy/coreに_dotblas.soができていてlddでlibatlas.so等にリンクされていることを確認してください。 - 別のディレクトリでnumpy.test()を実行して確認。
3でお気づきたと思いますが、GotoBLAS2を無理やりATLASだとNumPyに思わせてbuildしています。
GotoBLAS2やCBLASの時にやっていた謎のリンク(libptcblas.so etc.)はこのだったのです。
試しに5000×5000の行列のnp.dotを試してみるとたしかに4 threadsで実行されていることが確認できます。爆速です!
SciPy
- SciPyのソースを公式サイトからダウンロード&解凍。
- scipy/lib/lapack/__init__.pyとscipy/linalg/lapack.pyを以下のように編集
変更前from scipy.linalg import flapack from scipy.linalg import clapack _use_force_clapack = 1 if hasattr(clapack,'empty_module'): clapack = flapack _use_force_clapack = 0 elif hasattr(flapack,'empty_module'): flapack = clapack変更後
from scipy.linalg import flapack clapack = flapack _use_force_clapack = 0
- SciPyをbuild&install
$python setup.py build
$sudo python setup.py install - 他の ディレクトリでscipy.test()を実行して確認。
* ERROR: Failure: ImportError (/usr/local/lib/python2.7/dist-packages/scipy/linalg/atlas_version.so: undefined symbol: ATL_buildinfo)
* ERROR: Failure: ImportError (/usr/local/lib/python2.7/dist-packages/scipy/linalg/clapack.so: undefined symbol: clapack_sgesv)
の2つのエラーは無視しても大丈夫です。
2の操作はGotoBLAS2を無理やりATLASだと騙したために必要な操作です。ATLASにはATLAS CLAPACKと呼ばれるラッパーが付属しており、scipyはそれへのpythonのラッパーclapack.soを作成します。
しかし、ここでのlibatlas.so(実際にはlibgoto2.so)やliblapack.soにはそれらがが含まれていないため、clapackを無効にする設定です。
それではGotoBLASで楽しいNumPYライフを!!
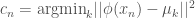
 はそれぞれn番目のサンプルの値、ラベル、特徴空間への写像関数、k番目のクラスターの特徴空間上の中心です。
はそれぞれn番目のサンプルの値、ラベル、特徴空間への写像関数、k番目のクラスターの特徴空間上の中心です。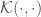 、k番目のクラスターの要素数
、k番目のクラスターの要素数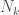 を使って整理すると最終的には以下のようになります。
を使って整理すると最終的には以下のようになります。
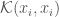 は常に一定なので計算しなくてもいいです。
は常に一定なので計算しなくてもいいです。
 を生成する。(dは次元)
を生成する。(dは次元)
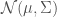 はどうするか?randnそのままではできないが、次のように生成できる。
はどうするか?randnそのままではできないが、次のように生成できる。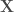 を上の例で示したように
を上の例で示したように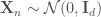
 に移動するのは簡単だ。
に移動するのは簡単だ。
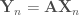
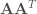 になるということを利用する。すなわち
になるということを利用する。すなわち
 を探すというわけであるが、これはまさにCholesky分解そのままである。
を探すというわけであるが、これはまさにCholesky分解そのままである。
